C# 的内存概念细节
"真正的程序员面向内存编程"
文档用途
清晰地解释重要的内存概念.
说明 C# 的部分语法和语言特性与内存的联系.
说明 Unity 中对内存的处理方式.
数据与地址
有关内存的一切问题, 都围绕着 数据 与 地址 展开.
C 语言中的优秀的设计, 也被沿用至 C# (的 unsafe 代码中).
C 语言中的数据与地址
C 语言中, 值类型用于代表数据. 指针类型用于代表地址.
(不使用取址符 &) 直接访问值类型变量, 得到的就是数据.
(不使用取值符 *) 直接访问指针类型变量, 得到的就是地址.
如果想知道值类型变量的地址, 需要使用取址符 &.
想知道指针类型变量所指向内存中的值就需要使用取值符 *.
例如任何一个变量都位于一个表示其自身所在位置的内存地址,
这个地址中存有数据 (该数据既可以是我们感兴趣的 值, 可以是任意内存 地址).
// C# 对于指针的简单使用案例.
public static unsafe void PointerDemo()
{
int number = 10;
int* p = &number;
*p = 20;
Console.WriteLine("number: " + number);
Console.WriteLine("&number: " + ((int)&number).ToString("X"));
Console.WriteLine("p: " + ((int)p).ToString("X"));
Console.WriteLine("*p: " + *p);
}$ dotnet run
number: 20
&number: 999BE5D8
p: 999BE5D8
*p: 20然而直接使用指针会容易出问题, 因此 C# 通过引入值类型和引用类型,
用以在大多数情况下代替 C 语言指针这套方案.
值类型与引用类型
| 中文 | 英文 |
|---|---|
| 值类型 | value type |
| 引用类型 | reference type |
值类型和引用类型的具体使用我们已经非常熟悉, 装箱拆箱也无需多言.
这里要讨论的重点在于: 值类型和引用类型在内存上的存储形态.
- 一个类型要么是值类型, 要么是引用类型, 区别在于拷贝方式.
值类型的数据总是拷贝值, 而引用类型的数据总是拷贝引用. - 值类型最好不要超过 64 字节, 引用类型可以很大.
微软没说为什么不应该让值类型超过 64 字节, 个人猜测是因为 CPU 缓存行通常是 64 字节,
如果 CPU 缓存行不能装下一个完整的值类型数据可能会有性能问题. - 一个常见的
错误论断: 值类型位于栈上, 引用类型位于堆上.
为什么说是错的呢? 我们举个例子:
public class MyClass
{
public int number;
public static void RunDemo()
{
var myClass = new MyClass();
// myClass 变量存储与栈上 stack
// myClass 引用的对象存储与堆上 heap
// myClass.number 存储与堆上 heap
}
}
public struct MyStruct
{
public float someFloat;
public MyClass myClass;
public static void RunDemo()
{
var myStruct = new MyStruct { myClass = new MyClass() };
// myStruct 变量存储与栈上 stack
// mySTruct.someFloat 存储与栈上 stack
// myStruct.myClass 所引用的对象地址存储与栈上 stack
// myStruct.myClass 所引用的对象存储与堆上 heap
}
}通过上面的例子可以得知:
- 引用类型的对象/实例只能被存储在堆中.
- 被引用类型封装的值类型 (该值类型作为引用类型的成员) 也被存储在堆中.
堆内存和栈内存
| 中文 | 英文 |
|---|---|
| 堆 | heap |
| 栈 | stack |
数据结构 中的堆和栈与 内存概念 中的堆和栈不是一回事.
两类概念容易混淆, 除了因为名称相同, 还有一个原因:
栈内存的分配与释放是先进后出, 这一行为与数据结构中的栈是一致的.
以下将要讨论的堆和栈都是指 内存概念.
- 一个进程只有一个堆, 一个线程只有一个栈.
因此栈上的数据仅能被其所在的线程访问. - 栈能够使用的内存空间远远小于堆.
栈的内存上限通常是是几 MB, 超过上限会触发StackOverflowException异常.
例如 64 位 window 系统栈内存上限为 1 MB, 64 位 Linux 系统栈内存上限为 10 MB. - 获取栈上数据的速度更快.
因为 CPU 提供指令集直接操作栈内存, 而操作堆内存需要通过操作系统调用来间接完成. - 栈主要用于对正在执行的代码保持追踪, 堆主要用于追踪对象 (或数据).
例如用于追踪函数调用的信息就存储于栈上. - 在函数中创建的变量, 不论该变量是值类型还是引用类型, 变量自身总是位于栈上.
如果该本地变量是引用类型, 且不为空, 那么其引用的对象位于堆上.
我们不仅可以将内存划分为栈内存和堆内存, 还可以将堆内存做进一步的划分:
将其分为托管堆内存和非托管堆内存, 详见下文.
托管与非托管
| 中文 | 英文 |
|---|---|
| 托管 | managed |
| 非托管 | unmanaged |
托管资源, 托管内存, 托管代码 等概念有所不同, 但相同之处是 "它们都被 运行时 托管".
托管内存 也被称之为 托管堆, 因为不管是托管还是非托管内存, 都位于堆上.非托管内存 (unmanaged memory) 也被称之为 原生内存 (native memory).
托管资源 是指托管堆上分配的内存资源, 由运行时在适当的时候调用垃圾回收器进行回收.
我们对类或者委托等引用类型使用 new 关键字, 那么创建的对象就被分配在托管内存中.
非托管资源 指的是运行时不知道如何回收的内存资源.
最常见的一类非托管资源如文件, 窗口, 网络连接, 数据库连接, 笔刷, 图标等.
对非托管资源需要编写代码手动回收.
为了更方便地释放非托管资源, C# 为其专门定义了: IDisposable 接口.
任何包含非托管资源的类, 都应该实现此接口, 以确保非托管资源的正确释放.
.Net 中非托管资源的手动申请与释放例子:Marshal 被定义在 System.Runtime.InteropServices 命名空间下.Span<T> 被定义在 System 命名空间下.
public static void MarshalDemo()
{
const int number = 100;
// 为非托管资源分配非托管内存
nint native = Marshal.AllocHGlobal(Marshal.SizeOf(typeof(int)) * number);
Span<int> nativeSpan;
unsafe { nativeSpan = new Span<int>(native.ToPointer(), number); }
int data = 0;
for (int ctr = 0; ctr < nativeSpan.Length; ctr++)
nativeSpan[ctr] = data++;
int nativeSum = 0;
foreach (int value in nativeSpan)
nativeSum += value;
Console.WriteLine($"The sum is {nativeSum}");
Marshal.FreeHGlobal(native); // 释放非托管资源
}$ dotnet run
The sum is 4950Unity 的 Native Container 就是对非托管内存的封装.
例如虽然 NativeArray<T> 本身是托管资源, 但是它包装了非托管资源 (非托管资源是它的成员), 并且可以通过类似于数组的语法访问其包装的非托管资源. NativaArray<T> 包装的非托管资源的释放逻辑写在 Dispose() 方法中, 因此我们需要通过调用此方法手动释放非托管资源.
非托管资源相比于托管资源的好处在于 不会产生 GC, 毕竟内存的回收需要手动写代码.
如果我们整个工程的完全不使用托管内存, 那么我们可以把 GC 给关掉.
虽然这么做有点极端, 不过确实看到有的开发团队采用了这种做法.
Unity 中非托管资源的手动申请与释放例子:UnsafeUtility 被定义在 Unity.Collections.LowLevel.Unsafe 命名空间下.

虽然 Unity 中也可以使用 Marshal 来分配非托管内存,
但用 Unity.Collections 及其子命名空间下的类型, 方法会更高效.
因为我们能够提前知道非托管资源的声明周期, 并根据生命周期来选择合适的 Allocator.
到此为止, 我们讨论了了非托管资源, 非托管内存, 那么非托管代码又是指什么呢?托管代码 就是执行过程交由运行时管理的代码.
非托管代码不被运行时托管, 而是由操作系统直接执行, 例如 C 语言写的代码.
C# 允许开发者越过托管代码与非托管代码的边界, 与非托管代码互操作 (P/Invoke).
另外在 C# 中被 unsafe 关键字包裹的代码块也是非托管代码,
此时内存操作, 类型检查等运行时提供的服务都被停用).\
建议阅读微软官方文档 什么是 "托管代码".
接下来需要讨论概念是: 非托管类型 (unmanaged type). 以下都是非托管类型:
- sbyte, byte, short, ushort, int, uint, long, ulong, char, float, double, decimal, bool.
- 所有 "成员变量都为非托管类型" 的结构体.
- 所有枚举类型.
- 所有指针类型.
在 C# 7.3 及以前的语法中, 还限制作为非托管类型的结构体不能是构造类型 (构造类型是指包含至少一个泛型参数的类型), 但从 C# 8.0 开始, 没有了这一限制.
为了理解非托管类型, 我们只需要记住一点: 非托管类型能够作为一个整体被分配在栈上.
这意味着我们可以在 "一段连续的栈内存上" 分配多个非托管类型的实例, 也可以创建指针指向非托管类型.
另外, 泛型参数的约束关键词 unmanaged 的作用就是约束泛型参数为非托管类型.
public struct Coords<T> where T : unmanaged
{
public T x;
public T y;
}Blittable 类型
Blittable 翻译为 "二进制兼容" , 也可以翻译成 "可直接复制到本机结构中的类型".
我们在这里只使用英文名称, 因为 blittable 没有被广泛认可的中文翻译.
来自 微软官方文档 (中文) 的一段话:
"大多数数据类型在托管和非托管内存中具有共同的表示形式,
而且不需要互操作封送处理程序进行特殊处理.
这些类型称为 blittable 类型, 因为它们在托管和非托管代码之间传递时不需要进行转换.
从平台调用返回的结构必须是 blittable 类型. 平台调用不支持返回类型为 non-blittable 结构."
上面这段话中, 我们已经熟悉了托管与非托管内存, 托管与非托管代码等概念.
唯一需要说明的是 互操作封送处理程序 (interop marshaler).
由于非托管代码只能处理 blittable 类型的数据.
因此如果想把 non-blittable 类型的数据从栈或托管堆传递至非托管堆,
那么就需要 "互操作封送处理程序" 做转换操作.
举个例子:
public class MyClass { }
public struct MyStruct
{
public float someFloat;
public MyClass myClass;
}
public static void RunDemo()
{
var MyStruct = new MyStruct { myClass = new MyClass() };
// myStruct 变量存储与栈上 stack
// myStruct.someFloat 存储于栈上 stack
// myStruct.myClass 所引用的对象的地址被存储与栈上 stack
// myStruct.myClass 所引用的对象存储于堆上 heap
}上图中, myStruct 实例在内存中 "不连续", 因为 myStruct.myClass 所引用的对象被存储在内存中别的位置, myStruct.myClass 变量仅仅是一个地址.
此时如果想把 myStruct 传递到非托管内存, 就需要 "互操作封送处理程序" 将 myStruct.myClass 所引用的对象从原本的内存位置移动到 myStruct 实例所在的内存位置.
因此 MyStruct 就是 non-blittable 类型.
哪些属于 blittable, 哪些是 non-blittable 呢? 我们完全可以用上述标准做判断.
同时, 由于 blittable 类型特征明显, 数量有限, 我们可以直接记忆:
- C# 定义的一些基础类型: sbyte, byte, short, ushort, int, uint, long, ulong, float, double, System.IntPtr, System.UIntPtr.
- 元素是上述基础值类型的一维数组 (但包含这种数组的类型就是 non-blittable 了) .
- 所有只包含 blittable 类型 (和作为格式化类型进行封送的类) 成员的格式化的值类型.
我们来看看 blittable 类型在 Unity 中的使用场景: 将数据传入 Job, 做多线程并行计算.
Job System 所使用的线程由 Unity 的引擎代码 (C++) 创建并维护,
因此数据被传入 Job 后都被存储在非托管内存中 (数据被传入前可能在栈上或是托管堆上).
之所以 Job System 限制其获取的数据必须为 blittable 类型, 是因为这样可以直接把栈上或托管堆上的一段代表完整原始数据的连续内存复制到非托管堆上, 无需封送处理, 性能非常优秀.
IDisposable 接口
如前文所提到的, 非托管资源的释放需要我们手动操作. 如果一个类型中存在引用了非托管资源的成员, 那么就应该实现 IDisposable 接口, 以确保非托管资源的正确释放.
IDisposable 结构的实现有一个固定写法, 我们都应该用这种格式来写:
public class MyDisposableClass : IDisposable
{
// 为了避免 Dispose(bool) 方法被反复执行, 需要这个字段.
private bool isDisposed = false;
// 注意 "终结器" 调用 Dispose(bool) 方法时所传入的实参为 false.
// "终结器" 也被叫做 "析构函数", 但 "析构函数" 是 C++ 的术语, C# 中称之为 "终结器" 更准确.
~MyDisposableClass() => Dispose(false);
public void Dispose()
{
Dispose(true); // 注意这里实参为 true.
GC.SuppressFinalize(this); // 禁止 GC 调用终结器.
}
protected virtual void Dispose(bool disposing)
{
if (isDisposed) return;
if (disposing)
{
// todo: 释放这个类中的 "托管资源" (例如集合), 将相应的成员变量设置为 null.
// 因为我们在 Dispose() 中禁止了 GC 调用此对象的终结器, 所以需要我们手动释放.
}
// todo: 释放这个类中成员所引用的 "非托管对象" (例如文件句柄, 数据库连接).
// 放在此处, 无论是显式调用 Dispose 方法, 还是等终结器被调用, 都能确保非托管对象最终被释放.
isDisposed = true;
}
}创建实现了 IDisposable 接口的对象时, 可以使用 using 语句.
会在在变量超出作用域时自动调用 Dispose() 方法:
using var myDisposableClass = new MyDisposableClass();当可以使用 using 语句时, 应使用 using 语句替代对 Dispose() 的手动调用.
当无法使用 using 语句时, 再去手动调用 Dispose() 方法.
using 语句会自动创建 try / finnally 语句块, 即使出现异常, 也能确保 Dispose() 被调用.
有关 终结器 (Finalizer):
- struct 中不允许出现终结器, 只有 class 中才可以, 并且只能有一个.
- 执行垃圾回收之前系统会自动调用终结器 (除非手动禁止 GC 调用终结器) .
- 在终结器中包含大量释放资源的代码, 会降低 GC 的工作效率, 明显影响性能.
- 终结器不能被继承或重载.
而实现 IDispose() 接口的优势如下:
- 显式调用 Dispose() 方法, 可以及时地释放资源.
- 就算没有显式调用 Dispose() 方法, GC 也可以通过终结器来释放非托管资源.
另外 GC 本来就会回收托管资源, 从而可保证堆内存资源的正常释放. - 但由 GC 自动调用终结器会导致非托管资源未及时释放而造成内存的浪费.
因为没有终结器的对象在垃圾回收器第一次处理中便从内存中删除.
而含有终结器的对象, 需要两次, 第一次调用终结器, 第二次将对象从内存删除.
运行时 CLR
CLR 全称 Common Language Runtime, 可翻译为 "通用语言运行时" .
CLR 最开始是 .Net Framework 的运行时, 后来 .Net Core 出现后, 微软为之提供了一个开源的运行时叫做 Core CLR, 但是从 .Net 5 开始已经不再区分 CLR 和 Core CLR 了.
CLR 负责提取托管代码, 将其编译成机器代码, 然后执行它 (JIT 支持).
运行时还提供多个重要服务, 例如自动内存管理, 安全边界, 类型安全, 与非托管代码的互操作, 跨语言调试支持等等.
建议阅读知乎文章 什么是CLR.
需要注意的是, 我们所说的 运行时 不一定是指 CLR, 因为还存在其他的运行时.
例如在 Unity 中, 就提供了 mono 和 il2cpp 两个运行时.
而且就算是微软自家, 也还有 Native AOT 这个运行时.
CLR 和 mono 都是 JIT 运行时, 也可以被称之为虚拟机.
il2cpp 和 Native AOT 都是 AOT 运行时.
Unity 中的 GC
建议阅读知乎文章 理解Unity中的优化 (五) : 托管堆, 说得更详细.
该文章是对 Unity 官方文档的翻译, 可以直接阅读 Understanding the managed heap.
Unity 的 GC 机制, 使用了 Boehm GC 算法.
特点是是 非分代 (non-generational) 和 非压缩 (non-compacting).非分代 是指 GC 执行清理操作时, 必须遍历整个内存, 因而性能开销会随着内存占用一同上升.非压缩 意味着内存中的对象不会被重新定位, 去缩小对象之间的内存空隙.
如下图所示, 如果想在托管堆中创建一个对象, 虽然托管内存中还有空间, 这些内存空间并不连续, 所以可能没有一段足够大的连续的内存空间来放置这个对象, 此时运行时就需要向操作系统申请更多内存以容纳这个新的对象.

追踪内存分配的情况比较简单. 在 Unity CPU Profiler 中, 查看 GC Alloc 这一列.
这一列展示了在这一帧中, 托管堆的分配状况.
开启 "Deep Profiling" 选项, Profiler 能追踪是哪些方法分配了内存.
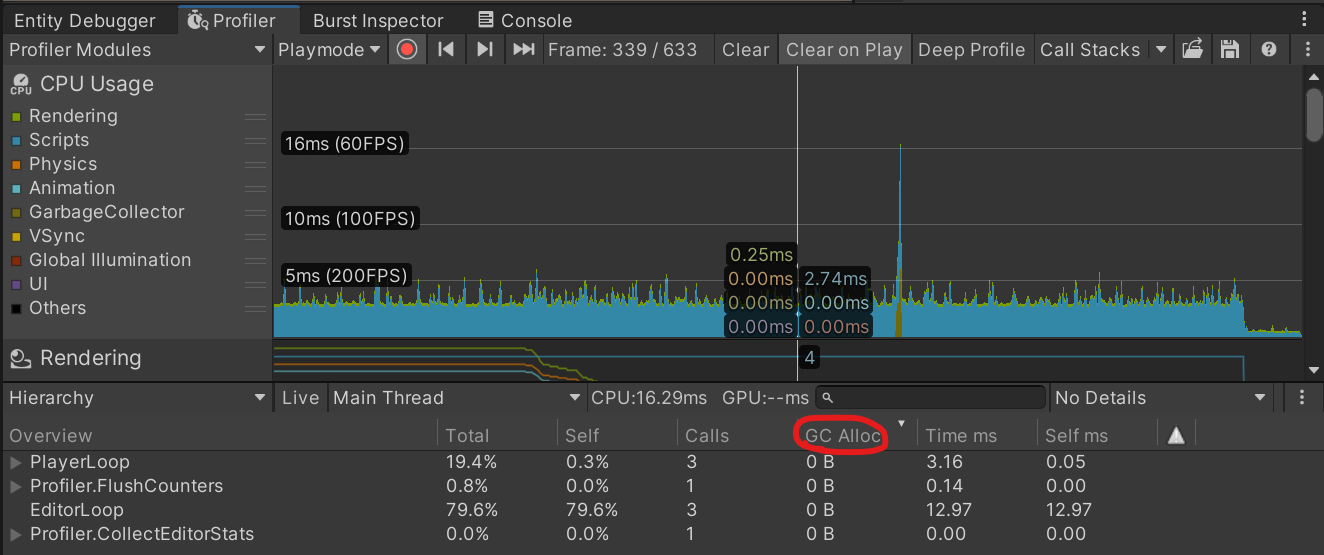
GC Alloc 统计的是 "在主线程中分配的堆内存" , 也就是说:
- 主线程外分配的内存无法被统计.
- 既包括托管堆, 也包括非托管堆.
当在Unity Editor下运行时, 有一些脚本方法会需要分配内存,
但是在打包后, 就不会有这个问题 (比如 GetComponent() 方法就是一个例子) .
GC 机制对于很多 App 的开发非常友好, 这样提高了开发效率.
因为不用随时担心内存泄漏问题, new 之后不需要手动回收.
但是 GC 对于游戏这种需要稳定帧率的应用场景非常不友好, 尤其是 Unity 的 GC 机制还不怎么智能 (相对于 .Net) , 因此我们应尽量避免托管内存的分配.
一张图看 Unity 的 GC 性能有多差, 下图为 Unity 与 .NET 6 的对比, 测试结果越低越好.
测试代码 传送门.
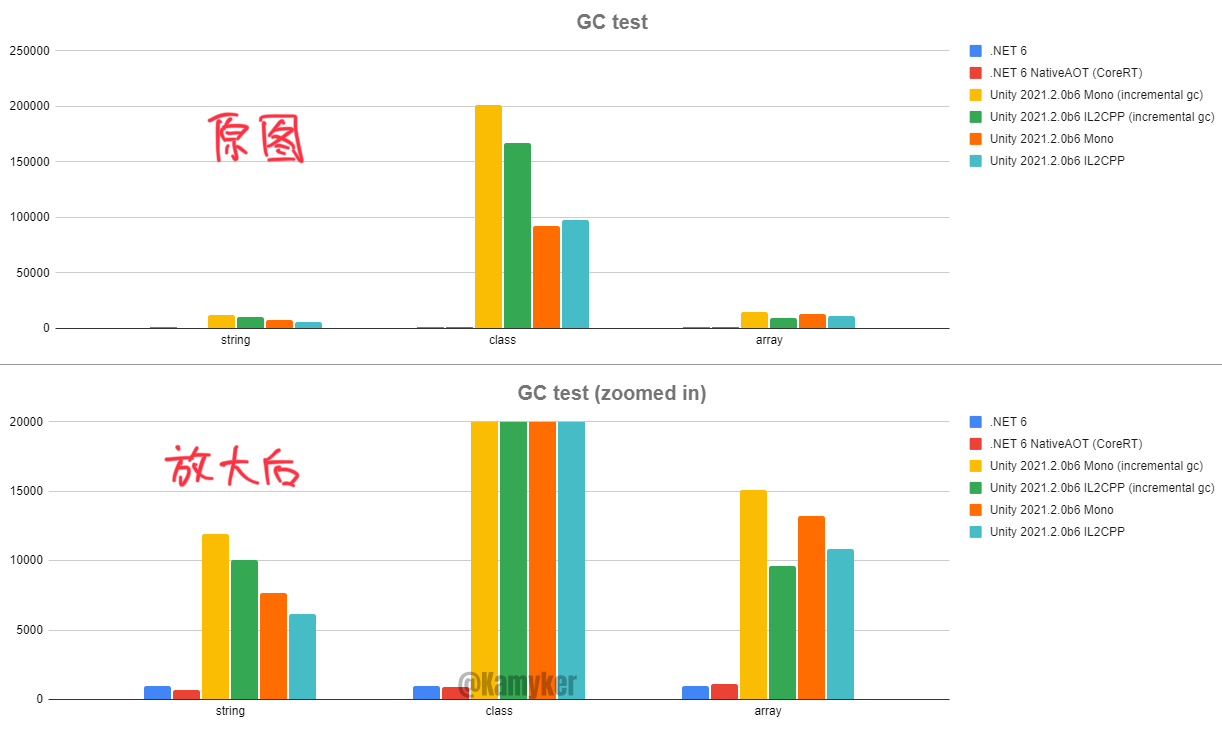
DOTS 技术其实就能很大程度上解决这个问题, 纯 ECS 可以做到 0 GC, 所有的内存要么在栈上分配, 要么在非托管堆上分配 (并手动回收). 但就实际情况而言, 我们还是得混合使用 UnityEngine 及其子命名空间下的 API, 此时就需要通过一些 "最佳实践" 来尽可能降低 GC.
理解Unity中的优化 (五) : 托管堆 就是一个不错最佳实践.
其中有关 闭包 的内容有必要专门在文档中说明, 详见下文.
匿名函数与闭包
Lambda 表达式和匿名方法统称为匿名函数.
从 C# 3 开始,匿名方法应完全被Lambda 表达式代替.
当使用匿名函数时, 需要注意:
- 在 C# 中, 所有方法的引用都是引用类型, 都会被分配到堆中.
把方法作为参数传递时, 都会产生临时的内存分配, 不管传递的是匿名方法还是已声明的方法.
虽然 C# 9.0 新增了函数指针, 不会为其分配堆内存, 因而是 0 GC 的.
但我们在 Unity 中目前还用不上, 毕竟 Unity 仅支持 C# 8.0 的语法.
- 将匿名函数转换为闭包会显著地增加传递闭包所需的内存.
在匿名函数内使用匿名函数外的变量, 则会使得匿名函数转换为闭包.
使用 Lambda 表达式可能会导致闭包的例子:
说明: 这是在 main() 方法中调用下图中的 RunExample() 方法得到的结果.
public class ClosureDemo
{
readonly Action[] myActions = new Action[3];
public void MyMethod()
{
for (int i = 0; i < myActions.Length; i++)
myActions[i] = () => Console.WriteLine(i);
foreach (Action myAction in myActions)
myAction();
}
public static void RunDemo()
{
ClosureDemo instance = new();
instance.MyMethod();
}
}$ dotnet run
3
3
3为什么上图中的代码的结果不是 012 而是 333 呢?
因为上图代码等效为下图中的代码:
public class ClosureDemo
{
readonly Action[] myActions = new Action[3];
public void MyMethod()
{
AnonymousClass anonymous = new();
for (int i = 0; i < myActions.Length; i++)
myActions[i] = () => Console.WriteLine(i);
for (anonymous.i = 0; anonymous.i < myActions.Length; anonymous.i++)
myActions[anonymous.i] = new Action(anonymous.Action);
foreach (Action myAction in myActions)
myAction();
}
public static void RunDemo()
{
ClosureDemo instance = new();
instance.MyMethod();
}
private sealed class AnonymousClass
{
public int i;
internal void Action() { Console.WriteLine(i); }
}
}编译器会生成类似上图中 AnonymousClass 这样的代码 (以 IL 而不是 C# 显示).
闭包带来的最大问题就是 GC, 而我们应当尽量避免 GC (尤其是对于 Unity 这种 GC 机制不优秀的运行时而言) .
这里举了个闭包的例子, 还不够详细. 建议阅读 反编译C#代码来看看闭包到底是什么.
这里直接列出有关闭包的结论:
- 闭包对象的生成次数与其使用的外部变量的作用域有关.
因此应尽量使用生命周期更长的变量, 不要图方便转存对象到本地变量.
如果引用循环中声明的本地变量, 则每个循环都会生成一个闭包对象. 如果使用方法中声明的本地变量, 则每次调用方法时都会生成一个闭包对象.
- 单个闭包对象的内存占用与其使用的变量有关.
- 当一个方法内有多个会产生闭包的匿名函数时, 它们会被自动合并成一个闭包对象.
- 如果匿名函数没有使用任何外部变量, 可以认为它和成员方法等效 (没有产生闭包) .
本地函数
下面一段换引用自 C# 首席设计师 Mads Torgersen:
"我们认为这个场景是有用的 —— 您需要一个辅助函数. 您仅能在单个函数中使用它, 并且它可能使用包含在该函数作用域内的变量和类型参数. 另一方面, 与 lambda 不同, 您不需要将其作为一个对象, 因此您不必在意是否要为它提供一个委托类型并分配一个实际的委托对象. 另外, 您可能希望它是递归的或泛型的, 或者将其作为迭代器实现."
本地函数用法举例:
public static int LocalFunction()
{
int localNumber = 10;
return Sum(20, 30);
// 本地函数, 没有堆内存分配, 不会出现闭包
int Sum(int a, int b) { return localNumber + a + b; }
}可以看看如果使用 Lambda 而不是本地函数, 上图的方法会被写成什么样:
public static int LambdaExpression()
{
int localNumber = 10;
// Lambda 表达式, 既有创建委托对象的内存分配, 也会出现闭包
Func<int, int, int> Sum = (a, b) => localNumber + a + b;
return Sum(20, 30);
}因此, 上图这种情况, 显然本地函数比 lambda 更好.
当 lambda 被转换成委托时, 本地函数在某些情境下应替代 lambda, 比如上面的例子.
但除了可能被转换成委托, lambda 还可能被转换成 表达式树, 此时 lambda 无可替代.
本地函数不仅仅在内存方面有优势. 由于此文档主要讨论内存, 因此如果想更详细地了解本地函数, 建议阅读知乎文章 C# 中的本地函数 和 Local functions (C# Programming Guide).
这里只写结论, 本地函数的优势:
- 本地函数是方法中的方法, 它还能出现在构造函数, 属性访问器, 事件访问器等成员中.
- 本地函数在功能上类似于 Lambda 表达式, 但它比 Lambda 表达式更加方便和清晰, 在分配和性能上也比 Lambda 表达式略占优势.
- 本地函数支持泛型和作为迭代器实现.
- 本地函数还有助于在迭代器方法和异步方法中立即显示异常.
大多数时候本地函数在能够替代 Lambda 表达式时避免产生闭包问题, 但仍需要注意:
- 如果本地函数被作为委托类型参数.
- 如果本地函数所使用的变量也被 Lambda 表达式所使用.
- 如果本地函数所使用的变量同时被另一个本地函数使用
(且这个本地函数被作为委托类型参数使用).
以上情况都会出现闭包, 但若想避免本地函数所产生的闭包问题, 原则很简单:
确保本地函数所使用的变量不被已有的闭包包含.
FAQ
问: 可空类型是值类型还是引用类型?
答: 值类型, 因为 int? 等同于 Nullable<int>, 而 Nullable<T> 的声明如下:
public struct Nullable<T> where T : struct