性能优化笔记
文档用途
记录 Bevy 的性能优化的原理与最佳实践.
参考 Unofficial Bevy Cheat Book - Performance Tunables.
开发阶段的性能取舍
通常我们并不会修改所依赖的 crate 的源代码, 只会频繁修改当前工程中的代码.
为了性能可以让所依赖的 crate 都在 debug mode 编译时采用高级别的优化,
同时让自己写的代码只做级别较低的优化 (兼顾编译速度和性能).
因此可以在 Cargo.toml 中做如编译设置:
[profile.dev]
# Enable a small amount of optimization in debug mode.
opt-level = 1
[profile.dev.package."*"]
# Enable high optimizations for dependencies (including Bevy).
opt-level = 3对不同类型线程的配置
Bevy 会创建 3 中不同用途的线程:
| 名称 | 用途 |
|---|---|
| I/O | 用于资源加载和网络等 I/O 逻辑 |
| AsyncCompute | 用于在后台处理与帧无关的逻辑 |
| Compute | 用于执行各种 system 和每帧都要执行的逻辑 |
默认情况下, Bevy 会按照为不同用途的线程分配数量:
| 名称 | 目标数量 |
|---|---|
| I/O | 目标是 25% 的 CPU 最大线程数, 最小为 1, 最大为 4 |
| AsyncCompute | 目标是 25% 的 CPU 最大线程数, 最小为 1, 最大为 4 |
| Compute | 剩余所有可用线程 |
实际情况举例
| CPU 最大线程数 | I/O | AsyncCompute | Compute |
|---|---|---|---|
| 1-3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 2 |
| 6 | 2 | 2 | 2 |
| 8 | 2 | 2 | 4 |
| 10 | 3 | 3 | 4 |
| 12 | 3 | 3 | 6 |
| 16 | 4 | 4 | 8 |
| 24 | 4 | 4 | 16 |
| 32 | 4 | 4 | 24 |
根据游戏的实际需求, 我们可能需要调整线程的分配方案:
如果在游戏逻辑中几乎不使用 AsyncCompute 类型的线程, 则应该限制这种类型的线程数量.
如果游戏中的资源都在专门的场景中加载好, 无需动态加载, 则应限制 I/O 类型线程的数量.
通过以下方式配置 Bevy 的线程分配策略:
use bevy::core::TaskPoolThreadAssignmentPolicy;
use bevy::tasks::available_parallelism;
App::new()
.add_plugins(DefaultPlugins.set(TaskPoolPlugin {
task_pool_options: TaskPoolOptions {
io: TaskPoolThreadAssignmentPolicy {
// 假设我们的游戏需要频繁加载资源, 因此需要较多的 I/O 线程
min_threads: 2,
max_threads: std::usize::MAX,
percent: 0.5, // 目标线程数是 50% 的 CPU 最大线程数
},
async_compute: TaskPoolThreadAssignmentPolicy {
// 假设我们几乎不使用 AsyncCompute, 但还是留一个线程以防万一
min_threads: 1,
max_threads: 1,
percent: 0.0,
},
compute: TaskPoolThreadAssignmentPolicy {
min_threads: available_parallelism() / 2,
max_threads: std::usize::MAX,
percent: 1., // 目标线程数为 "所有剩余可用线程数"
},
..Default::default()
},
}))
// ...
.run();渲染管线与输入延迟
Bevy 在默认的渲染管线中 (Pipelined Rendering Architecture), 会将当前帧的普通 system 与上一帧的 GPU-related system 并行执行. 这种策略对性能当然更好, 但是会造成输入延迟.
下图中的下半部分就是 Bevy 的默认渲染管线示意图, 上半部分代表禁用后的效果.
可以观察到默认渲染管线中, 玩家输入与画面显示之间的延迟为 2 帧, 禁用后为 1 帧.
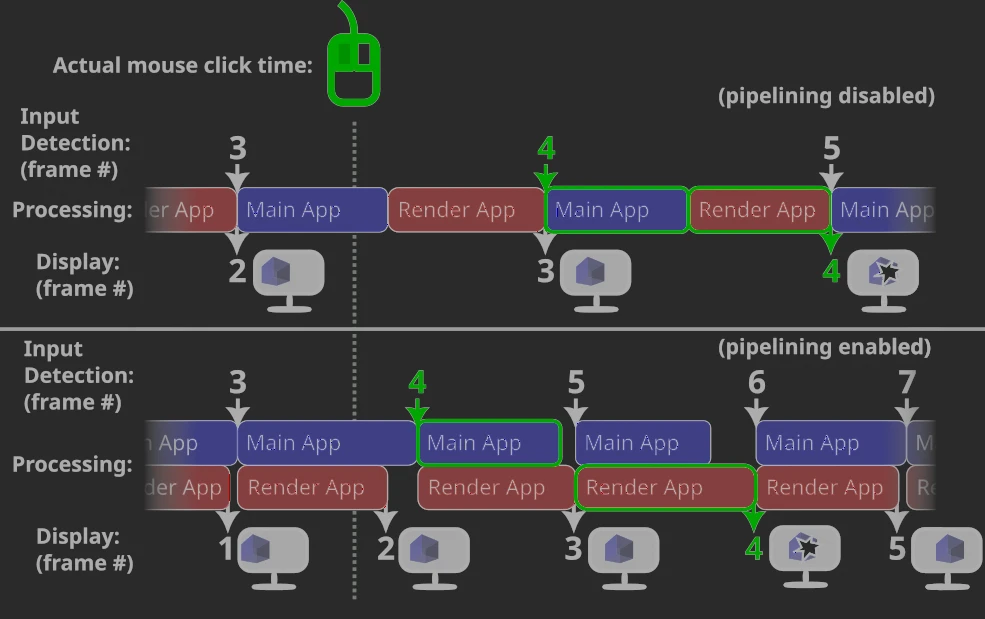
如果我们非常重视 "灵敏的操作反馈", 则可以考虑禁用 (以性能为代价).
通过以下方式禁用 Pipelined Rendering Architecture:
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
App::new()
.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>())
// ...
.run();Clustered Forward Renderer
Clustered Forward Renderer 的简单介绍:
将 viewport 空间切分成大量子空间 (形状类似于长方体), 统计每个子空间受到哪些灯光的影响.
在着色阶段, 通过某个片元 (fragment) 位于哪个子空间, 来判断这个片元需要计算哪些灯光.
从而不需要像传统的 forward rendering 那样为每个片元计算所有灯光, 以此提升性能.
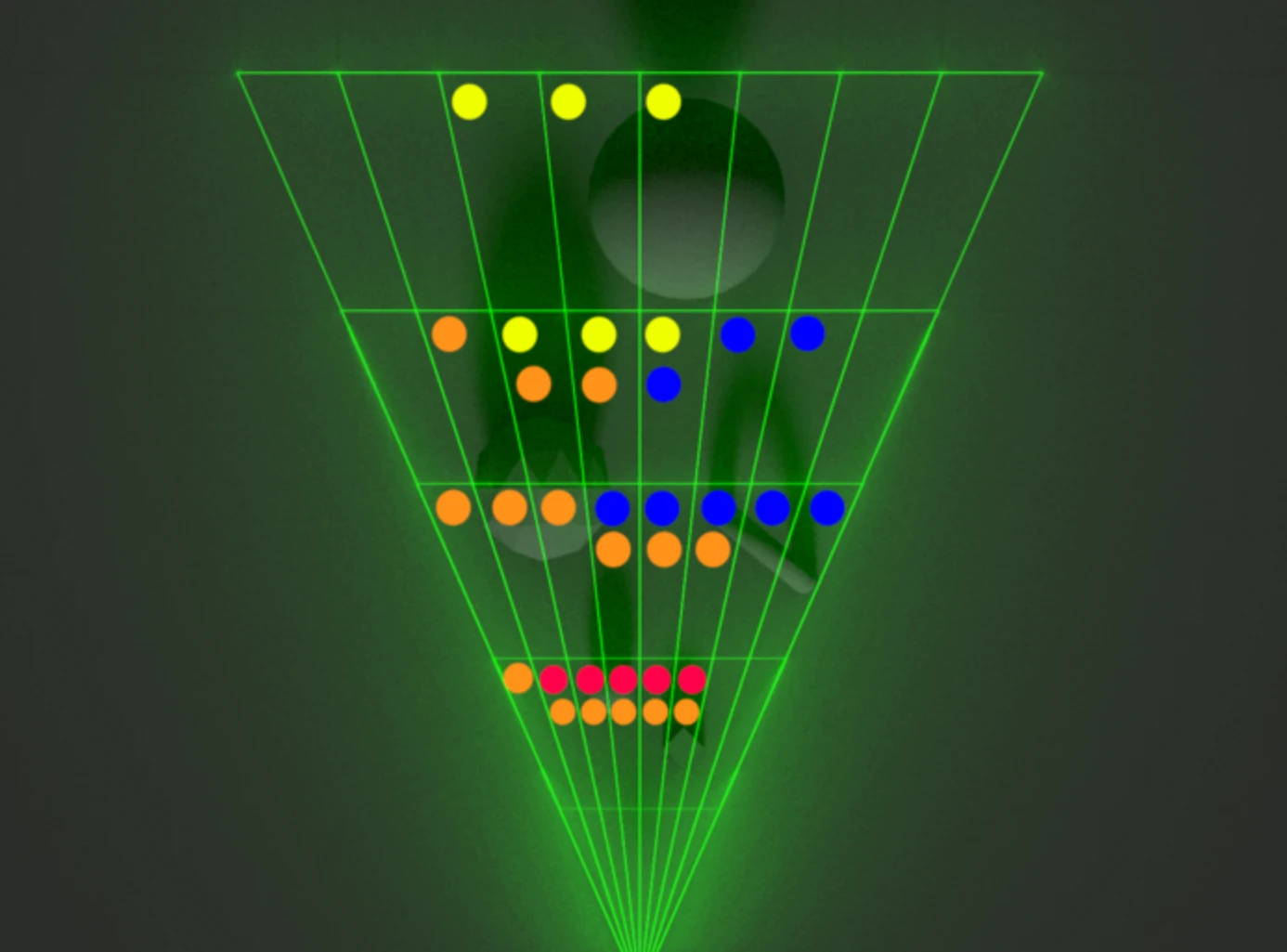
例如下图为渲染结果, 场景中存在几个不同颜色的灯光.

如果从侧面观察 viewport 空间, 就是下图中的锥形区域.
可以看到 viewport 被切分成了多个子空间, 并且每个子空间标记了所有对其造成影响的灯光.
INFO
上图中只能看到摄像机局部坐标系 z 轴与 x 轴的切割. (Bevy 使用以 y 轴为纵轴的右手坐标系).
需要脑补的是 x 轴与 y 轴的切割, 结果就是将 viewport 切分成一个个类似于长方体的区域.
某些情况下, 我们可以根据实际情况调整 Bevy 对于 viewport 的切分方式.
例如上帝视角的策略类游戏, 在 z 轴上的切分多半没有意义, 此时可以做出如下调整:
use bevy::pbr::ClusterConfig;
commands.spawn((
Camera3dBundle {
// ... your 3D camera configuration
..Default::default()
},
ClusterConfig::FixedZ {
// 4096 clusters is the Bevy default
// if you don't have many lights, you can reduce this value
total: 4096,
// Bevy default is 24 Z-slices
// For a top-down-view game, 1 is probably optimal.
z_slices: 1,
dynamic_resizing: true,
z_config: Default::default(),
}
));如果场景中灯光数量极少, 或是灯光几乎影响场景中几乎所有物体,
那么就没有必使用这套 viewport 切分方案. 可以通过这种方式禁用:
commands.spawn((
Camera3dBundle {
// ... your 3D camera configuration
..Default::default()
},
ClusterConfig::Single,
));Parallel Query
在默认情况下我们在 system 中使用的 Query 会在单线程中被迭代.
// 单线程迭代
fn move_system(time: Res<Time>, mut sprites: Query<(&mut Transform, &Velocity)>) {
sprites.iter_mut().for_each(|(mut transform, velocity)| {
transform.translation += velocity.0.extend(0.) * time.delta_seconds();
});
}如果我们希望 Query 在多个线程上迭代, 那么就需要用到 par_iter() 或 par_iter_mut().
Query 将被分成多份, 在多个线程上迭代, 默认情况下份数等于线程数.
// 多线程迭代
fn move_system(time: Res<Time>, mut sprites: Query<(&mut Transform, &Velocity)>) {
sprites
.iter_mut()
.par_iter_mut()
.for_each(|(mut transform, velocity)| {
transform.translation += velocity.0.extend(0.) * time.delta_seconds();
});
}WARNING
Parallel Query 只适用于计算任务繁重的情况, 在计算任务轻量的情况下反而对性能有害.